





Moving from simple risk management to real resilience is a critical new capability that organizations are striving to attain. Teams seek to quickly mature resilience as we re-open (and sometimes close again) our businesses, countries and economies in the COVID-19 world. Organizations that do this well and become ‘anti-fragile’ will thrive – those that do not – will find themselves being driven out and battered by new waves of change. In our posts on Risk Quantification, the Digital Impact Chain and how COVID-19 Has Changed The We Do Risk – Forever, we focused on how to risk management is changing and becoming more aligned with scoring techniques based on multiple factors from both technology and business stakeholders. This blog post takes Risk Quantification a step further and redefines resilience in terms of becoming anti-fragile.

Traditionally, we think of resilience in terms of how quickly something can ‘bounce back’ from an impact. Business continuity teams focus on metrics such as the number of days or hours to return to operations (RTO) or a recovery point (along a process) objective (RPO). RTO and RPO are typically used to measure resilience goals through business impact assessments (BIAs). Disaster recovery teams execute playbooks that have been tested – often months back in a different environment – and struggle to bring processes back online after an incident
But all that has changed with the COVID-19 pandemic and the ‘call for change’ that worldwide protests are demanding. In a world where human speed is outflanked by digital transaction speed and decisions are made using real-time analytics – old approaches to business continuity and disaster recovery simply don’t cut it. Developing real resilience means becoming ‘anti-fragile’ – a concept spearheaded by Nassim Taleb author of Fooled by Randomness, The Black Swan and Antifragile. Organizations and processes become anti-fragile by continually testing with small shocks to the integrated fabric of people, process and technology. Why? Because risks are interconnected. Risks can cascade.
A COVID-19 hot spot can close access to a critical single-source supplier. Creating greater diversity and fairness at work can mean reworking resource plans and partnerships – in a good and sustainable way. In a world where rare events dominate the landscape because risks have cascaded in ways we’ve not yet anticipated, anti-fragile is the route to real resilience.
If you have been able to incorporate Risk Quantification, with a bottoms-up, top-down approach to score risks, by aligning operational, infotech, security and cyber teams, you can now start moving from risk to true resilience. But to develop anti-fragility, your teams must do more – and increase the scope of resilience across a digital environment – not only within your organization, but also across your vendors and cloud service providers (CSPs). This means aligning processes, such as incident response that now have a larger, wider-spread impact. across many distributed, virtual stakeholder groups.
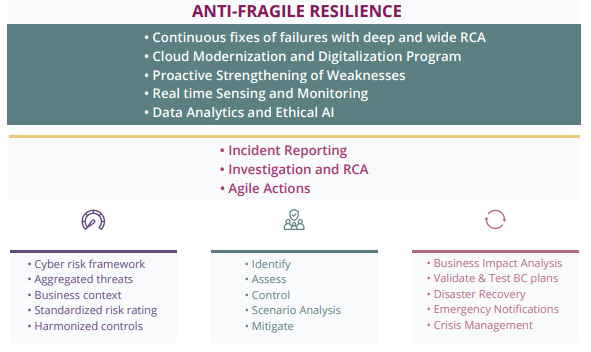
Anti-fragile as a goal, especially with increasing digital transformation, assumes your teams see where there can be a chain reaction across the technology and business process workflow – with upstream and downstream processes across CSPs connected to other third and fourth parties. The best way to start building anti-fragility into resilience programs is to start acting with agility. Begin building a strong capability to quickly adapt, leverage early warning signals and have tested, executable plans to bounce back on. Let’s look at some general categories with examples of how our current reactive practice can be transformed by building anti-fragility into our GRC programs and technologies.
CONTROLS
• Reactive practice – Go through a (sometimes long and protracted) remediation action plan as a result of a (sometime long and protracted) assessment or audit.
• Anti-fragile practice – Fix control/test failures faster and completely. Address it as a fix right away prior to it getting tied up in a prolonged process. Look across your environment and fix similar problems proactively: Ask where else could this be happening with the same failed control.
ROOT CAUSE CANALYSIS (RCA)
• Reactive practice – Fix an issue with a BAND-AID due to resource and budget constraints.
• Anti-fragile practice – Fix issues by going deep and wide. Conduct a real RCA by asking the Five Whys involving the right people across the organization and CSPs. Use this a point of real learning.
WEAKNESSES
• Reactive practice – Wait until an emerging risk shows up as a failure in order to get the remediation budget.
• Anti-fragile practice – Be proactive on suspected weaknesses. For example: cyber controls are increasing with X-From Home (work, school, medical check-ups, news, recreation, social visits, advice, etc.). XFH has pushed the envelope and hackers have upped the ante. Also, look at the infrastructure. Is there a power outage? That could be critical if a doctor is WFH and on a call with a patient! What risk can you transfer? Where does your accountability stop and where is it shared? Think through your way of responding.
CLOUD
• Reactive practice – Use your own data center with older apps to run portions of the business.
• Anti-fragile practice – Be proactive on cloud modernization: If you have 20 cloud service providers (CSPs) now, think about everything that could be improved with leading, safer, more secure scalable CSPs. Proactively define your standardization strategy, such as, your SSO strategy across the cloud? You’ll need this kind of standardization to scale as an enterprise
REAL TIME SENSING AND MONITORING
• Reactive practice – Use continuous controls to monitor in isolated areas, not looking at the opportunity to automate the end-end process.
• Anti-fragile practice – Up your game on monitoring and sensing mechanisms. We’re seeing more and more utilities, cable operators and other providers using IOT and remote sensing technologies – where real-time data is being pulled and continuously analyzed – and proactively avoiding risks. This puts an entirely new view on resilience. Think about your business and technology processes. What needs to be digitalized and what can you continuously sense and monitor?
DATA ANALYTICS AND ARTIFICAL INTELLIGENCE (AI)
• Reactive practice – Use metrics in isolated areas, not looking at the opportunity to build analytics into the end-end process.
• Anti-fragile practice – Get proactive on predictive analytics where it makes sense. Understand your ethical risks and put an AI governance program in place that provides visibility into common pitfalls. Test for bias of the creator or bias in your data. Your organization needs clean, relevant data and transparent algorithms for optimal decision-making.
Remember, business continuity planning is not enough. Real resilience requires a commitment to developing anti-fragility across the entire fabric of your extended enterprise. We are in an unprecedented age of change – more digitalization and greater diversity, in both people and technologies – transforming our third-party relationships and the way we work. Anticipate and be ready to embrace this change! Build anti-fragile concepts into your resilience strategy and plans.
About the author:
Yo McDonald, Vice President, Customer Success and Engagement, MetricStream, is a seasoned executive in Governance, Risk and Compliance (GRC) consulting and product solutions. She drives customer engagement and retention, while fostering a culture of customer success at MetricStream.
Dr. Vidya Phalke is Chief Innovation and Cloud Officer.

Subscribe for Latest Updates
Subscribe Now